ASCIISmuggler Angriff auf Mastodon

Dieser Vortrag wurde zum 39C3 eingereicht und abgelehnt. Ich fand heraus, dass ein auf Ascii Smuggler basierender Angriff die Filterregeln für Posts in Mastodon außer Kraft setzt. Damit sind diese Filter derzeit für den Schutz vor Spam und anderem unerwünschten Inhalt quasi nutzlos geworden.
Die Präsentation zu dem Vortrag, den ich dazu eigentlich halten wollte ist hier zu finden.
Responsible Disclosure
Ich habe am 29.8.2025 eine EMail an die dafür vorgesehene Adresse security@joinmastodon.org gesendet -mit einer Zusammenfassung meiner Erkenntnisse und einer Anleitung zum Nachvollziehen sowie einem Screenshot, der das Verhalten im Webfrontend von Mastodon zeigt.Keine Reaktion.
Am 14.9.2025 sendete ich eine weitere EMail an dieselbe Adresse mit einem Hinweis auf meine erste und der Information, dass ich vorhabe, diese Findings am Ende des Jahres auf einer Konferenz zu präsentieren und im Web zu veröffentlichen.
Reaktion: "Wir schauen es uns an"
Seither - keine weitere Interaktion
Daher bin ich der Meinung, dass ich die Informationen jetzt freigeben kann - es sind immerhin mehr als nur die gewöhnlichen drei Wochen vergangen...
Die Auswirkungen
Wie gesagt: Filter lassen sich in Mastodon verbergen. Das betrifft natürlich auch alle anderen Anwendungen die auf dem zugrundeliegenden Protokoll basieren und deren Clients nicht die in diesem Artikel beschriebenen Gegenmaßnahmen ergreifen. Andererseits kann man damit effektiv Posts verbergen - die Suche nach Schlüsselbegriffen bringt keine Ergebnisse, wenn man die Posts mittels der Mechanismen des AsciiSmuggler behandelt. In beiden Fällen bleiben die Posts für menschliche Teilnehmer lesbar - menschliche Teilnehmer merken von der Manipulation nichts.Ich denke aber, dass dieser Mechanismus nicht nur Mastodon oder das sogenannte Fediverse betrifft und möchte einen eindringlichen Appell an alle richten, jeden textuellen Input mit größter Vorsicht zu bearbeiten und per default alles auszufiltern, was nicht der Unicode BMP angehört.
Allgemeines
Unicode war ein großer Fortschritt gegenüber EBCDIC, ASCII und Codepages. Aber Unicode ist auch eine Angriffsoberfläche weil es nicht nur Zeichen kodiert, sondern auch Markup-Features beinhaltet. Unicode ist nicht nur einfach Text: Steuerzeichen, unsichtbarer Inhalt und so weiter sorgen immer wieder für Überraschungen. In der Vergangenheit waren das zum Beispiel Trojan Source und Ascii Smuggler. Ich zeige, warum solche Angriffe funktionieren, wozu man sie heutzutage benutzen kann und gebe Tipps, wie man eigene Implementierungen schützen kann...Das, was ich als Features von Unicode bezeichne sind Dinge, die meiner Ansicht nach in Zeichenkodierungen nichts verloren haben, sondern in Markup-Systeme gehören. Zeichenkodierungen und Markup sind zwei verschiedene Dinge und sollten nicht vermischt werden. Geschieht dies dennoch (und sind sich Anwendungsentwickler dessen nicht bewusst), erhöht das die Angriffsoberfläche gewaltig. Ich werde kurz auf diverse solche Features eingehen und dazu nochmals Trojan Source- und Ascii Smuggler-Angriffe vorstellen.
Ich werde zeigen, wie man die Technik aus Ascii-Smuggler benutzen kann, um Text zu verstecken: Damit ist es derzeit noch möglich, Textfilter ins Leere laufen zu lassen - sei es zum Verbergen von Posts bei der Prüfung der politischen Gesinnung vor der Einreise oder einfach nur beim Filtern unerwünschter Posts in sozialen Medien.
Der Mechanismus
Unicode enthält neben "normalen" Codepoints, die Schriftzeichen darstellen noch andere Codepoints, die Aufgaben haben, die keine sichtbaren Zeichen erzeugen. Das kann das Ändern des Verhaltens des darstellenden Systems (BiDi-Codes) ebenso sein, wie Kommentare für die Verarbeitung des Textes - sogenannte (Language) Tags. Alle diese Codepoints sollen normalerweise nicht dargestellt werden. Wir werden gleih sehen, dass nicht alle Anwendungen dies auch umsetzen. Diejenigen, die diese Anweisung umsetzen, tun das auf zwei verschiedene Weisen: Es gibt Anwendungen, die diese Codepoints nur bei der Darstellung unterdrücken und solche, die es korrekterweise bei Darstellung und Verarbeitung tun.Und dann gibt es noch LLMs - der ursprüngliche Ascii Smuggler-Angriff beruhte darauf, dass die Language-Tags, die das gesamte Ascii-Alphabet abbilden als Teil des Textes aufgefasst wurden und man somit Prompt Injection-Angriffe durchführen konnte: Es wurden nicht alle Language-Tags ausgefiltert, sondern nur die Start- und Ende-Marker entfernt und der dazwischen eingebettete Text wurde zum Inhalt des Dokuments als es das LLM als Prompt interpretierte. Das ist natürlich die mit Abstand bescheuertste Idee, mit Language-Tags umzugehen - wie bereits gesagt: der Standard sagt, dass solche Zeichen unterdrückt werden sollen - nicht dass man alles Mögliche und Unmögliche versucht, sie doch noch irgendwie als Text zu interpretieren!
Aber das brachte mich dazu, mich zunächst darüber zu informieren, wo diese Probleme eventuell noch lauern könnten:
Die Analyse
Nachdem ich auf das Problem der Language Tags aufmerksam geworden war (und auf das verwandte der Surrogates), habe ich mich zunächst gefragt, ob dieses Problem viel grundlegender sein könnte und daher zunächst geprüft, ob man auf diese Art und Weise eventuell das Parsen von Zahlenwerten angreifen könnte: ein - als Language Tag getarnt würde dann etwa dafür sorgen, dass der Anwedner die Zahl als 3 wahrnimmt, während der Wert nach dem Parsen -3 ergibt. Ich prüfte mehrere Sprachen:
- C
- C++
- C# (.NET)
- Python
- Java
Als nächstes prüfte ich verschiedene Anwendungen. Dabei ging es zunächst darum, ob sich die enthaltenen Language Tags störend bei der Darstellung der Texte auswirken würden. Anschließend testete ich dann, ob die enthaltenen Tags eventuell die Verarbeitung der Texte stören würden. Hier die Ergebnisse:
Die sQLshell zeigt Pseudozeichen an, wenn Language Tags enthalten sind - so sieht der (aufmerksame) Anwender, dass im Text Codepoints enthalten sind, die da eigentlkich nicht hingehören. Dies trifft sowohl auf Text im SQL-Editor zu, wie auch auf solchen im Script-Editor (Java bzw. BeanShell) und auch bei der Darstellung von Abfrageergebnissen. Versucht man entsprechende SQL-Statements zur Ausführung an die Datenbank zu senden, bemerkt das die sQLshell und verhindert das Absenden mit einer Fehlermeldung. Die Editoren zeigen die entsprechenden Codepoints deutlich an, wenn die Option zur Anzeige der nicht-druckbaren Zeichen aktiviert wird, die ich ursprünglich als Gegenmaßnahme gegen Trojan Source eingebaut hatte.
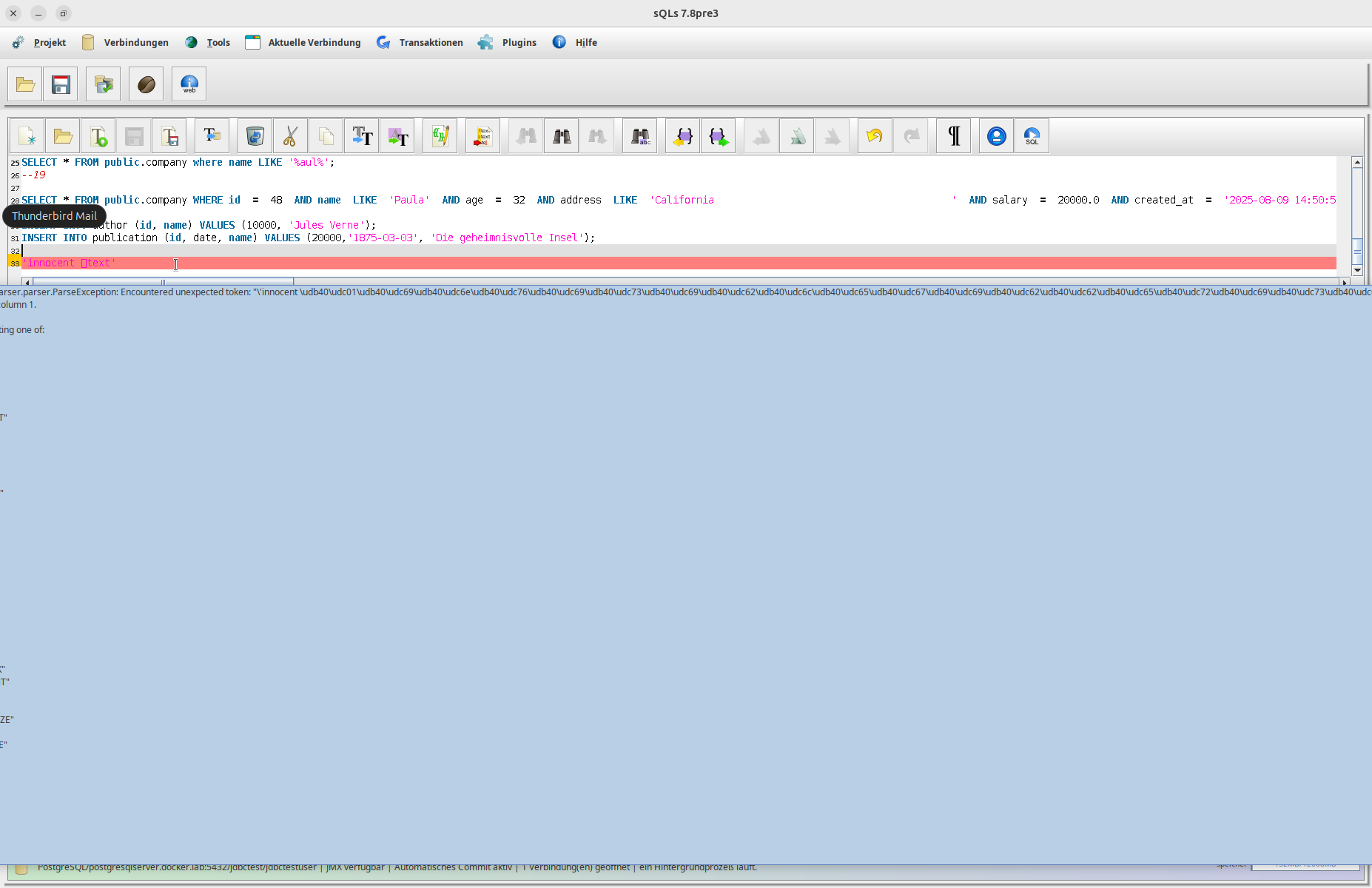 SQL-Editor in der sQLshell
SQL-Editor in der sQLshell
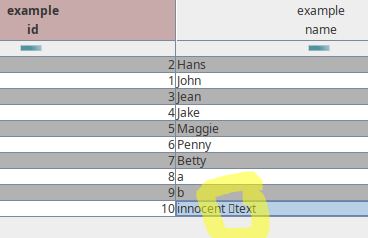 Abfrageergebnisse in der sQLshell
Abfrageergebnisse in der sQLshell
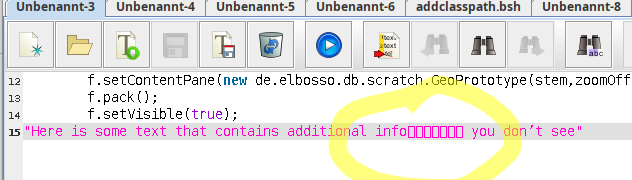 Skript-Editor in der sQLshell
Skript-Editor in der sQLshell
Wie schon im Fall des Trojan Source-Problems schaute ich mir auch Webanwendungen an - ich benutzte dafür GitHub, GitLab und Codeberg. Es stellte sich geraus, dass alle drei Systeme sich gleich verhalten: Sie speichern die zusätzlichen Codepoints, stellen sie aber nicht dar. Daher sieht der Text in allen drei folgenden Screenshots für den Anwender vollkommen unverdächtig aus:
 Kommentar mit eingebetteten Language Tags in GitLab
Kommentar mit eingebetteten Language Tags in GitLab
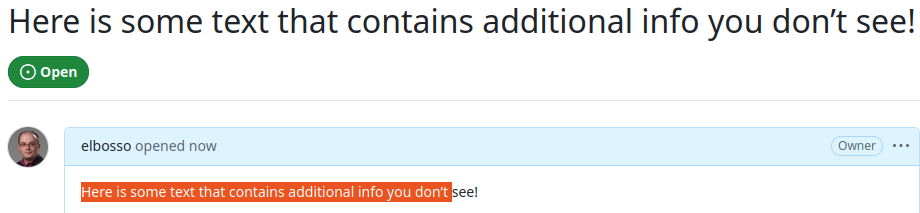 Issue mit eingebetteten Language Tags in GitHub
Issue mit eingebetteten Language Tags in GitHub
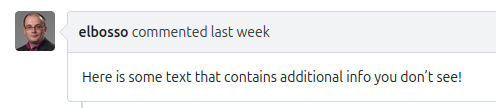 Kommentar mit eingebetteten Language Tags in Codeberg
Kommentar mit eingebetteten Language Tags in Codeberg
Hier werden jetzt noch einige Beispiele anderer Anwendungen und ihres Verhaltens und Reaktion auf Text mit eingebetteten Language Tags präsentiert:
 In NeoVim in einem XTerm sieht der aufmerksame Anwender Pseudozeichen und ist gewarnt
In NeoVim in einem XTerm sieht der aufmerksame Anwender Pseudozeichen und ist gewarnt
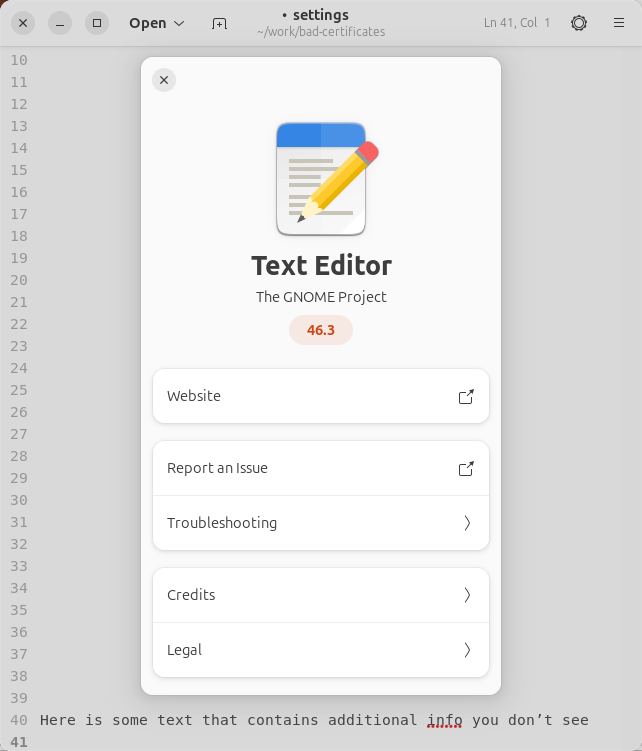 Im Gnome Text Editor bemerkt der Anwender nichts davon.
Im Gnome Text Editor bemerkt der Anwender nichts davon.
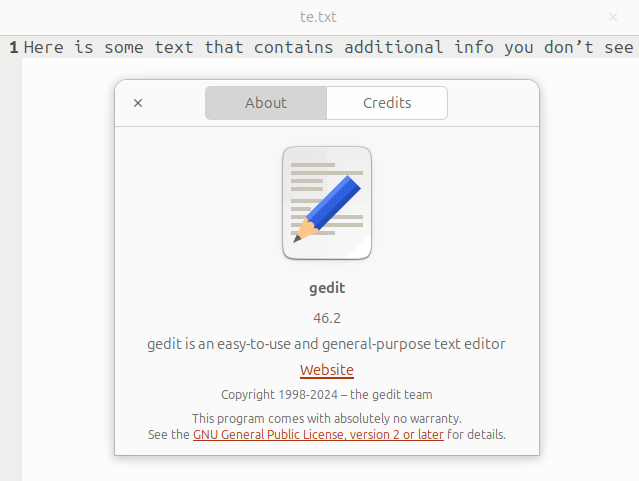 In Gedit bemerkt der Anwender ebenfalls nichts davon
In Gedit bemerkt der Anwender ebenfalls nichts davon
Ich habe vorhin diverse Webanwendungen untersucht - wie steht es aber mit ganz normalen Input-Elementen in HTML-Dokumenten? Leider muss man hier feststellen, dass auch diese Eingabeelemente die Darstellung der Language Tags komplett unterdrücken, beim Absenden aber alle Codepoints - einschließlich der Language Tags übermitteln:
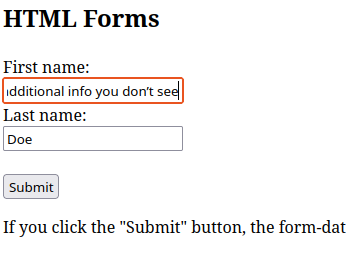 Input-Elemente in HTML-Dokumenten
Input-Elemente in HTML-Dokumenten
 Der tatsächliche Inhalt...
Der tatsächliche Inhalt...
Der Exploit
An dieser Stelle angekommen habe ich überlegt, was sich mit den gesammelten Informationen anfangen ließe: Zunächst versuchte ich, in diversen Anwendungen, die die Darstellung der Language Tags komplett unterdrückten, diese aber im Text beließen, Text-Operationen durchzuführen. Dazu zählten das Sortieren von Zeilen, das Suchen von Test und ähnliches.Für mich wenig überraschend funktionierte nichts davon. Am überraschendsten ist das natürlich für Anwender von Lösungen, die die Language Tags in der Anzeige komplett unterdrücken, sie jedoch im Text belassen.
Suchen von Text ist aber ein sehr spezieller Use Case von Text Matching. Allgemeiner kann man diesen Use Case wie folgt formulieren: Finde matching Text und führe die Aktion ... auf die Fundstellen aus. Bei der suche nach Text in einem Editor / einer IDE ist die Aktion das Hervorheben der Fundstelle(n), das Zählen aller gefundenen Vorkommen und das gezielte Springen zur vorhergehenden oder nächsten Fundstelle.
Es gibt aber noch andere. An dieser Stelle angekommen fiel mir der Use Case Filterung ein: Filtere alle Beiträge, in denen der Suchbegriff vorkommt und zeige die Beiträge (nicht mehr) in der Timeline an.
Das brachte mich zu meinem Experiment mit Mastodon bzw. dem Fediverse: Ich kontaktierte eine Person und fragte sie, ob sie sich mit dem Filtern von Beiträgen auskenne. Sie richtete daraufhin sofort einen entsprechenden Filter für den Begriff ossifrage - der Screenshot hier zeigt, dass ein Beitrag unterdrückt wurde und ein Beitrag, bei dem ich einige Language Tags in dem Begriff versteckt hatte durch den Filter geschlüpft ist und trotzdem angezeigt wird:
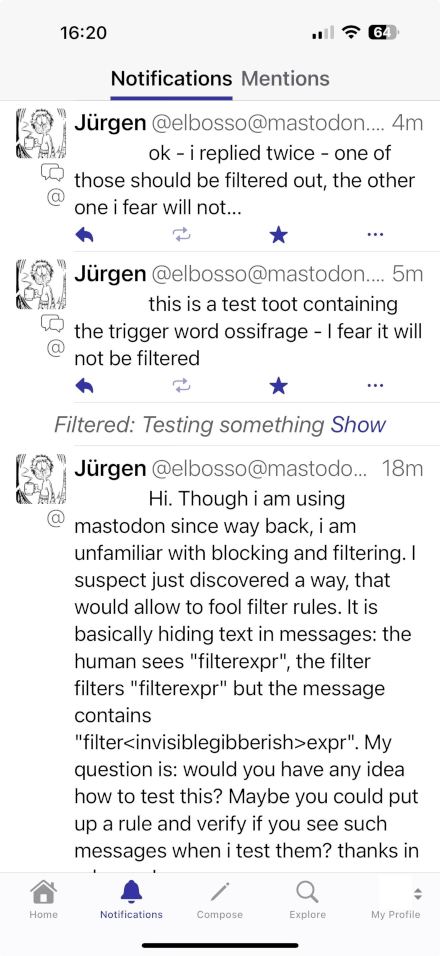 Mastodon Filterregeln überlistet
Mastodon Filterregeln überlistet
Das zeigt - da auch hier die Language Tags gar nicht angezeigt werden, die in der Message enthalten sind - dass die Filterregeln in Mastodon / Fediverse, die dafür da sind, Anwender vor unerwünschtem Inhalt zu schützen, sehr leicht umgangen werden können.
Die Reaktion - oder besser das Fehlen jeder Reaktion - auf meine Meldung lässt mich davon ausgehen, dass dies immer noch der Fall ist und sich uin absehbarer Zukunft nicht ändern wird.
Der Ratschlag
- Entferne für Textoperationen wie Suchen oder Filtern alle Language Tags und sonstigen nicht druckbaren Zeichen aus dem Text
- Zeige nicht druckbare Zeichen oder Language Tags an, wenn sie nicht aus dem Text entfernt werden pder gib dem Anwender wenigstens dei Möglichkeit, eine solche Anzeige zu aktivieren
Interessanterweise existieren Anwendungen, die diese Tips bereits beherzigen: Ich habe weitere Versuche unternommen, andere Anwendungen und Protokolle damit anzugreifen und war sehr erstaunt - und zufrieden - dass EMail beispielsweise zumindest in Teilen dagegen immun zu sein scheint: Thunderbird hat alle so behandelten EMails asl Junk kategorisiert. Dadurch neugierig geworden habe ich weiter recherchiert und herausgefunden, dass das Vorhandensein dieser Codepoints schon recht lange als Zeichen für Junk-Mails benutzt wird, was man zum Beispiel beim Studium der Beispiel-Mails für Phishing der TU München erkennen kann.




![]()
![]()


![]()
Vor 5 Jahren hier im Blog
-
Keycloak und LDAP
11.07.2021
Nachdem ich neulich bereits über die erfolgreiche Kopplung zwischen Keycloak und LDAP berichtete, bin ich noch einige Schritte weitergegangen...
Weiterlesen
Tags
AI und ML Android Basteln C und C++ Chaos Datenbanken Docker dWb+ ESP Wifi Garten Geo Go GUI Hardware Java Jupyter JupyterBinder Komponenten Links Linux Markdown Markup Music Numerik OpenSource PKI-X.509-CA Präsentationen Python QBrowser Rants Raspi Revisited Security Software-Test sQLshell TeleGrafana Verschiedenes Video Virtualisierung Windows Upcoming...
Neueste Artikel
-
SBOMs für alte Java-Projekte II
Ich habe bereits vor einiger Zeit eine Möglichkeit präsentiert, SBOMs aus alten Java-Projekten zu erstellen. Ich bin neulich einer speziellen Form von Java-Projekten begegnet, die mich dazu bewogen hat, mich auch hierfür an der (nachträglichen) Erstellung einer SBOM zu versuchen...
Weiterlesen -
Mini-QR und Silverbullet neu im Docker-Zoo
Ich habe eine weitere Alternative zum Aufnehmen von Notizen in meinen Docker-Zoo aufgenommen
Weiterlesen -
Neue Möglichkeiten zur Visualisierung von Modulverbindungen
Ich habe wieder einmal im Urlaub grundlegende Architekturänderung in meinem Framework, das auch die Grundlage für die sQLshell und dWb+ darstellt vorgenommen.
Weiterlesen
Manche nennen es Blog, manche Web-Seite - ich schreibe hier hin und wieder über meine Erlebnisse, Rückschläge und Erleuchtungen bei meinen Hobbies.
Wer daran teilhaben und eventuell sogar davon profitieren möchte, muss damit leben, daß ich hin und wieder kleine Ausflüge in Bereiche mache, die nichts mit IT, Administration oder Softwareentwicklung zu tun haben.
Ich wünsche allen Lesern viel Spaß und hin und wieder einen kleinen AHA!-Effekt...
PS: Meine öffentlichen Codeberg-Repositories findet man hier.