sQLshell und xinclude
Die sQLshell unterstützt in ihrer neuesten Version das Aufteilen der Daten beim XML-Import auf mehrere Dateien.
![]() Die sQLshell ist in der Lage, ein Datenmodell in ein XML-Format zu überführen. Dabei wird eine XML-Datei erstellt, die
die Daten aller Tabellen enthält. Weiterhin entsteht ein XML Schema als xsd-Datei, das die Struktur des
Datenmodells widerspiegelt. Dieses Schema wird beim Import eingelesen. Anhand der darin enthaltenen Informationen
werden die benötigten Tabellen und Constraints angelegt, damit anschließend die Daten in die Tabellen
eingefügt werden können.
Die sQLshell ist in der Lage, ein Datenmodell in ein XML-Format zu überführen. Dabei wird eine XML-Datei erstellt, die
die Daten aller Tabellen enthält. Weiterhin entsteht ein XML Schema als xsd-Datei, das die Struktur des
Datenmodells widerspiegelt. Dieses Schema wird beim Import eingelesen. Anhand der darin enthaltenen Informationen
werden die benötigten Tabellen und Constraints angelegt, damit anschließend die Daten in die Tabellen
eingefügt werden können.
Die neueste Version der sQLshell erlaubt es, die enge Beschränkung auf exakt eine XML-Datei aufzuheben: die sQLshell kann beim Import nun mit xinclude-Tags umgehen. Damit ist es mglich, die Daten eines Datenmodells auf beliebig viele Dateien zu verteilen. Beim Export erstellt die sQLshell nach wie vor nur eine XML-Datei. Daher ist diese Neuerung besonders für Anwender interessant, die Daten aus Drittsystemen mittels der sQLshell in eine Datenbank einlesen möchten.
Unten sind drei Dateien angehängt, die die Vorgehensweise illustrieren: Die Datei EXAMPLE.xsd beinhaltet das Schema des zu importierenden Datenmodells, die Datei EXAMPLE_PART1.xml wird beim Importieren ausgewählt. Sie enthält eine xinclude-Referenz auf die Datei EXAMPLE_PART2.xml, deren Daten dadurch ebenfalls importiert werden.
Das kann man am besten mit einer HSQLDB-in memory-Datenbank ausprobieren. Zum Erstellen dieser Datenbank
erzeugt man eine neue Verbindung mit folgenden Eigenschaften:
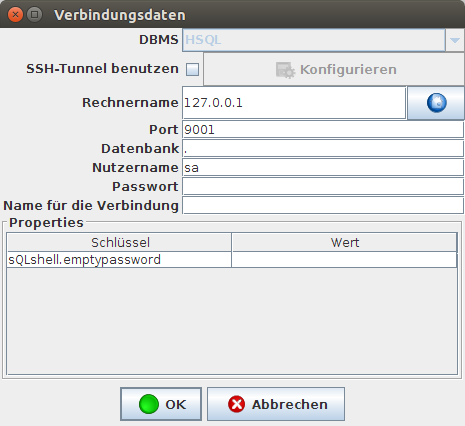 Verbindung zu einer in-memory Datenbank für Testzwecke
Verbindung zu einer in-memory Datenbank für Testzwecke






![]()
![]()


![]()
Vor 5 Jahren hier im Blog
-
Keycloak und LDAP
11.07.2021
Nachdem ich neulich bereits über die erfolgreiche Kopplung zwischen Keycloak und LDAP berichtete, bin ich noch einige Schritte weitergegangen...
Weiterlesen
Tags
AI und ML Android Basteln C und C++ Chaos Datenbanken Docker dWb+ ESP Wifi Garten Geo Go GUI Hardware Java Jupyter JupyterBinder Komponenten Links Linux Markdown Markup Music Numerik OpenSource PKI-X.509-CA Präsentationen Python QBrowser Rants Raspi Revisited Security Software-Test sQLshell TeleGrafana Verschiedenes Video Virtualisierung Windows Upcoming...
Neueste Artikel
-
SBOMs für alte Java-Projekte II
Ich habe bereits vor einiger Zeit eine Möglichkeit präsentiert, SBOMs aus alten Java-Projekten zu erstellen. Ich bin neulich einer speziellen Form von Java-Projekten begegnet, die mich dazu bewogen hat, mich auch hierfür an der (nachträglichen) Erstellung einer SBOM zu versuchen...
Weiterlesen -
Mini-QR und Silverbullet neu im Docker-Zoo
Ich habe eine weitere Alternative zum Aufnehmen von Notizen in meinen Docker-Zoo aufgenommen
Weiterlesen -
Neue Möglichkeiten zur Visualisierung von Modulverbindungen
Ich habe wieder einmal im Urlaub grundlegende Architekturänderung in meinem Framework, das auch die Grundlage für die sQLshell und dWb+ darstellt vorgenommen.
Weiterlesen
Manche nennen es Blog, manche Web-Seite - ich schreibe hier hin und wieder über meine Erlebnisse, Rückschläge und Erleuchtungen bei meinen Hobbies.
Wer daran teilhaben und eventuell sogar davon profitieren möchte, muss damit leben, daß ich hin und wieder kleine Ausflüge in Bereiche mache, die nichts mit IT, Administration oder Softwareentwicklung zu tun haben.
Ich wünsche allen Lesern viel Spaß und hin und wieder einen kleinen AHA!-Effekt...
PS: Meine öffentlichen Codeberg-Repositories findet man hier.